
Il paraîtrait que l’on peut faire dire ce que l’on veut aux chiffres ? Cela voudrait-il dire que l’on peut influencer un questionnaire en ligne, et obtenir des résultats biaisés ?
Par exemple, obtenir 6% de bonnes réponses à une question pour les 119 premières personnes y ayant répondu, puis bondir à 20% pour les 126 personnes suivantes ? C’est ce que j’ai observé sur un questionnaire que j’ai posté récemment.
Mais comment est-il possible d’obtenir un écart aussi important ?
Le questionnaire
Il s’agit d’un questionnaire inventé par Hans Rosling, un médecin et statisticien suédois. Il l’a créé afin de prouver que nous vivons tous avec une vision déformée de notre propre monde. Les questions portent sur des sujets liés à la démographie mondiale, ainsi que le développement économique des différents pays du monde. Et nous sommes tous hyper mauvais dans ce domaine ! Par exemple, cela touche aux sujets suivants :
- L’espérance de vie moyenne dans le monde,
- Le taux de scolarisation des filles par rapport aux garçons,
- Les tendances de mortalité causée par des catastrophes naturelles, etc…
Mon article sur le questionnaire, le livre associé (Factfulness), et le « pourquoi du comment » est plus détaillé, mais en gros : nous basons notre vision du monde sur des chiffres qui sont vieux de plusieurs décennies, nous avons tendance à imaginer le pire, nous sommes trop concentrés sur le sensationnel… Bref, notre propre cerveau se joue de nous, et nous sommes trop pessimistes quant à l’état général du monde.
LIRE L’ANALYSE COMPLETE SUR FACTFULNESS
La chronologie des publictions
Le 27 juin 2020 : je poste le tweet n°1, avec un lien vers le questionnaire. Ce sera l’unique fois que le questionnaire sera posté « sec », sans commentaire de ma part.
Le 29 juin 2020 : je poste l’article qui analyse les résultats dudit questionnaire, avec un embed du questionnaire au début de l’article, invitant le lecteur à y répondre. Je poste aussi le tweet n°2, qui présente un lien vers l’article.
Le 17 juillet 2020 : j’analyse à nouveau les résultats a posteriori, par curiosité.
Dans l’analyse d’origine, effectivement, la tendance prédite par le créateur des questions était confirmée : les résultats ne sont pas géniaux. Le nombre moyen de bonnes réponses était de 3.08 / 13, et la réponse avec le pire taux de bonnes réponses était à peine à 6% ! Mais c’est normal nous dit Hans Rosling : nous sommes pessimistes et biaisés…
Comparaison des résultats avant et après la publication de l’article
Par curiosité, 15 jours après la publication de l’article, je suis allé voir les résultats, et voilà ce que j’observe, en coupant en deux groupes les réponses au questionnaire :
- GROUPE 1 – les 119 réponses obtenus AVANT la publication de l’article.
- GROUPE 2 – les 126 réponses obtenues APRES la publication de l’article.
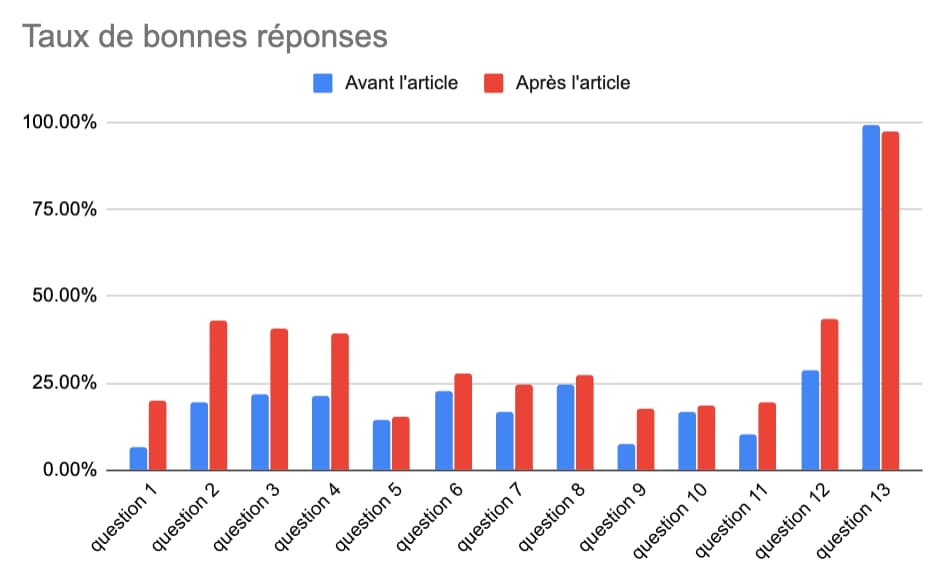
Donc, sur deux échantillons de quasiment la même taille, on obtient des résultats franchement différents. Entre le premier et le second, la moyenne augmente de 40%, passant de 3.08 à 4.30 sur 13. Toutes les questions sauf une ont un meilleur taux de bonnes réponses pour le GROUPE 2. On va même jusqu’à plus de tripler le taux de bonnes réponses pour l’une des questions…
On est là sur des écarts très significatifs ! Le GROUPE 2, ceux qui ont rempli le questionnaire après publication de l’article, a été bien meilleur. Beaucoup plus optimistes…
Et la question que je me pose : est-ce une coïncidence ?

Pourquoi ces différences ? Théories…
Théorie 1 – auto-censure
La première fois que j’ai publié le questionnaire, le 27 juin 2020, le ton du tweet était très très neutre. Il ne dévoilait rien sur le questionnaire lui-même ou sur le contexte dans lequel je le partageais :
Pour un prochain article sur mon blog, j’ai besoin de toi ! Ce serait cool de prendre 5 minutes pour remplir ce questionnaire ! Pas de spoiler dans les commentaires après.
https://twitter.com/VincentCourson/status/1276824608650547201
Ce qui fait que les personnes du GROUPE 1 y sont allées sans aucun préjugé, et ont sans doute répondu de manière très « naturelle », sans se méfier plus que ça.
En revanche, à partir du moment où j’ai fait la première analyse, le ton du titre de l’article et des tweets suivants a vraiment changé :
J’ai demandé à mes followers de répondre à un questionnaire sur l’état démographique et économique du monde : les résultats sont franchement mauvais (score moyen de 3.08 sur 13) ! Mais il y a une explication…
https://twitter.com/VincentCourson/status/1277933417666052097
Factfulness – Pourquoi nous ne comprenons pas le monde dans lequel nous vivons ?
Titre de l’article sur humeurweb.com
Du coup, il est logique de supposer que le GROUPE 2, en lisant ces messages avant ou au moment d’atterrir sur l’article, se soient auto-censuré au moment de répondre au questionnaire… « Si je pense que la réponse est 20%, mais qu’apparemment tout le monde se trompe, je vais plutôt répondre 60%. » On se rapproche du biais d’ancrage en psychologie.

Un argument supplémentaire appuie cette théorie : la seule question qui obtient un score moins bon après la publication de l’article est précisément celle qui a été incluse pour montrer que dans certains cas, nous ne nous trompons pas. C’est une question qui parle du réchauffement planétaire (les explications plus complètes dans l’article complet). Avant la publication de l’article, une seule personne s’est trompée. Après la publication, 3 personnes se sont trompées. Elles se seraient donc auto-censurées, dans l’autre sens. Elles auraient douté de leur capacité à bien répondre, et sont allé vers une réponse moins naturelle…
Théorie 2 – Remplissage du questionnaire après lecture de l’article
Ici, on observe une corrélation étrange :
- Dans l’article complet d’analyse, j’avais pointé du doigt spécifiquement 3 questions où le taux de bonnes réponses était particulièrement bas : les questions 1, 9, et 11.
- Les 3 mêmes questions font partie des 5 questions qui ont vu le plus grand bond dans la proportion de bonnes réponses entre le GROUPE 1 et le GROUPE 2 ! (respectivement +197.5%, +132.7%, et +91.9%).
On pourrait donc supposer que les personnes du groupe 2 ont plutôt rempli le questionnaire après la lecture de l’article. Et on donc fait particulièrement attention aux questions qui avaient été utilisées comme exemple dans l’article…
Théorie 3 – Problème dans la taille d’échantillon
Potentiellement, l’analyse entière est inutile, car un échantillon de seulement 100 et quelques personnes est trop petit pour se faire une idée statistiquement pertinente… Certes. Plus d’infos ci-dessous.
Conclusion
Je pense donc que le simple fait d’avoir intégré le questionnaire au début de l’article précédent a biaisé la suite des résultats. Il s’agit sans doute d’une combinaison des 3 théories exposées ci-dessus.
C’est selon moi un bel exemple d’un biais méthodologique qui peut impacter la pertinence d’un questionnaire. En gros, les sujets humains sont constamment soumis à des stimuli, et intègrent activement tous les éléments connexes à une situation pour produire une action dans un contexte donné. Ce qui veut dire que si on change le contexte, on peut changer les actions des humains. Et donc dans notre cas ici : en changeant son contexte, j’ai influencé le questionnaire en ligne.

Une solution pour confirmer cette théorie : obtenir de nouvelles réponses à analyser, collectées à nouveau dans un formulaire partagé « sec », donc sans contexte. Si les 120 prochaines réponses retournent aux niveaux d’avant l’article, on aura prouvé que j’ai sans doute biaisé mes réponses en intégrant le questionnaire à l’article… Et on augmente aussi la taille d’échantillon, par la même occasion. 🙂
Donc n’hésite pas à m’aider, cher lecteur, en postant ou envoyant le questionnaire à tes amis et sur les réseaux sociaux, sans ajouter de commentaires sur celui-ci : pas de spoiler ! https://forms.gle/K128Mya6q9mMP37Y6
La suite au prochain épisode !